

Meta punya dilepaskan entri terbaru dalam seri model AI generatif sumber terbuka Llama: Llama 3. Atau, lebih tepatnya, perusahaan telah membuat dua model sumber terbuka dalam keluarga Llama 3 yang baru, dan sisanya akan hadir pada tanggal mendatang yang tidak ditentukan.
Meta mendeskripsikan model baru — Llama 3 8B, yang berisi 8 miliar parameter, dan Llama 3 70B, yang berisi 70 miliar parameter — sebagai “lompatan besar” dibandingkan model Llama generasi sebelumnya, Llama 2 8B dan Llama 2 70B, dari segi kinerja. (Parameter pada dasarnya menentukan keterampilan model AI dalam suatu masalah, seperti menganalisis dan menghasilkan teks; model dengan jumlah parameter yang lebih tinggi, secara umum, lebih mampu daripada model dengan jumlah parameter yang lebih rendah.) Faktanya, Meta mengatakan bahwa, untuk jumlah parameternya masing-masing, Llama 3 8B dan Llama 3 70B — dilatih pada dua 24.000 cluster GPU yang dibuat khusus — adalah adalah salah satu model AI generatif dengan performa terbaik yang ada saat ini.
Klaim yang cukup besar untuk dibuat. Jadi bagaimana Meta mendukungnya? Nah, perusahaan menunjuk pada skor model Llama 3 pada tolok ukur AI populer seperti MMLU (yang berupaya mengukur pengetahuan), ARC (yang berupaya mengukur perolehan keterampilan) dan DROP (yang menguji penalaran model pada potongan teks). Seperti yang telah kami tulis sebelumnya, kegunaan — dan validitas — tolok ukur ini masih diperdebatkan. Namun baik atau buruk, mereka tetap menjadi salah satu dari sedikit cara standar yang digunakan pemain AI seperti Meta untuk mengevaluasi model mereka.
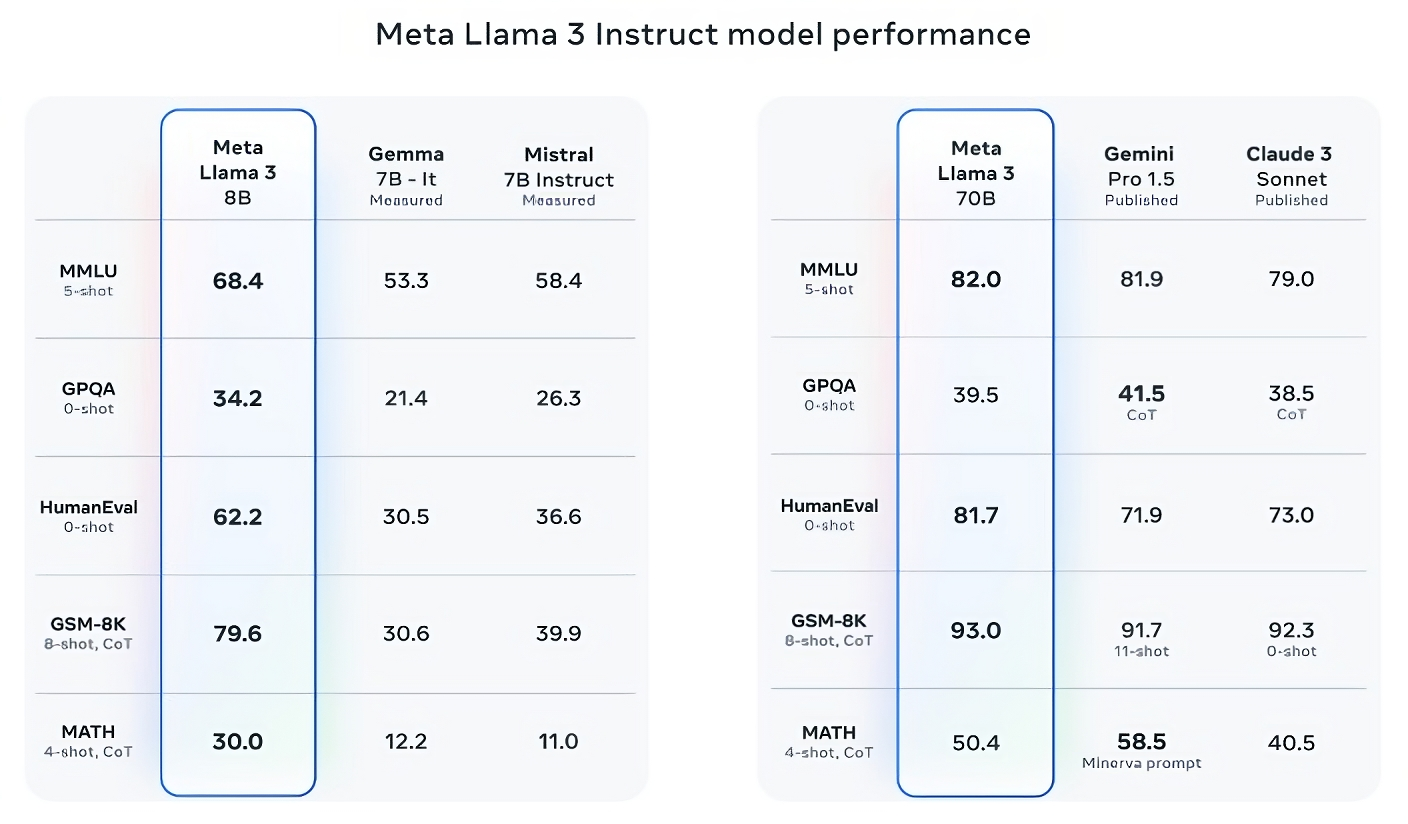
Llama 3 8B mengungguli model sumber terbuka lainnya seperti Mistral 7B dari Mistral dan Gemma 7B dari Google, keduanya berisi 7 miliar parameter, pada setidaknya sembilan tolok ukur: MMLU, ARC, DROP, GPQA (seperangkat biologi, fisika, dan kimia- pertanyaan terkait), HumanEval (tes pembuatan kode), GSM-8K (masalah kata matematika), MATH (tolok ukur matematika lainnya), AGIEval (satu set tes pemecahan masalah) dan BIG-Bench Hard (evaluasi penalaran yang masuk akal).
Sekarang, Mistral 7B dan Gemma 7B tidak sepenuhnya berada di garis terdepan (Mistral 7B dirilis September lalu), dan dalam beberapa benchmark yang dikutip Meta, Llama 3 8B hanya mendapat skor beberapa poin persentase lebih tinggi dari keduanya. Namun Meta juga mengklaim bahwa model Llama 3 dengan jumlah parameter lebih besar, Llama 3 70B, mampu bersaing dengan model AI generatif unggulan termasuk Gemini 1.5 Pro, yang terbaru dalam seri Gemini Google.
Kredit Gambar: Meta
Llama 3 70B mengalahkan Gemini 1.5 Pro pada MMLU, HumanEval, dan GSM-8K, dan — meskipun tidak menyaingi model Anthropic yang paling berkinerja, Claude 3 Opus — Llama 3 70B mendapat skor lebih baik daripada model terlemah di seri Claude 3, Claude 3 Sonnet, pada lima benchmark (MMLU, GPQA, HumanEval, GSM-8K dan MATH).
Kredit Gambar: Meta
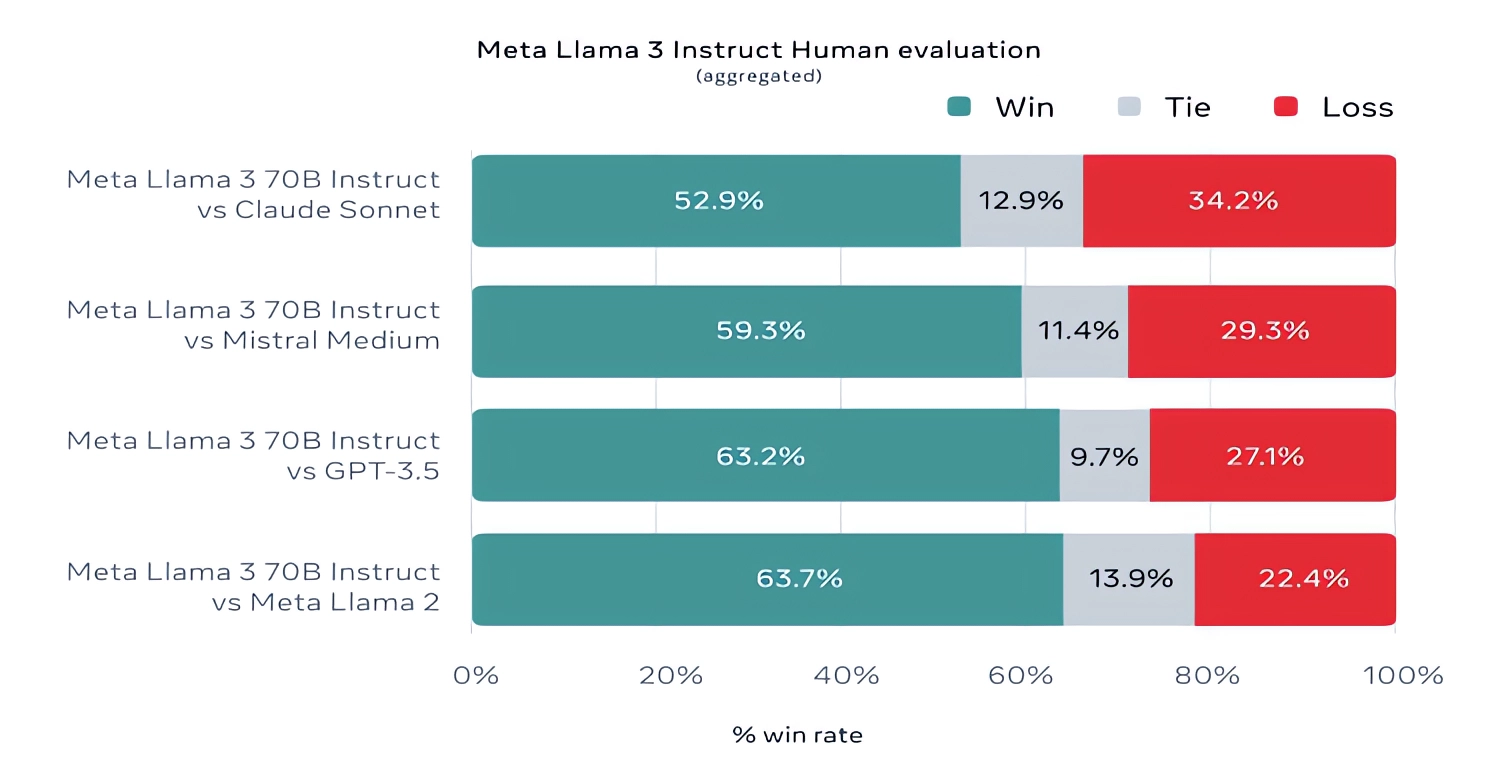
Untuk manfaatnya, Meta juga mengembangkan rangkaian pengujiannya sendiri yang mencakup kasus penggunaan mulai dari pengkodean dan pembuatan tulisan hingga penalaran hingga ringkasan, dan — kejutan! — Llama 3 70B unggul dibandingkan model Mistral Medium dari Mistral, GPT-3.5 OpenAI, dan Claude Sonnet. Meta mengatakan bahwa mereka membatasi tim pemodelannya mengakses set untuk menjaga objektivitas, tetapi jelas – mengingat Meta sendiri yang merancang tes tersebut – hasilnya harus diambil dengan hati-hati.
Kredit Gambar: Meta
Secara lebih kualitatif, Meta mengatakan bahwa pengguna model Llama baru harus mengharapkan lebih banyak “kemampuan pengendalian”, kemungkinan lebih rendah untuk menolak menjawab pertanyaan, dan akurasi yang lebih tinggi pada pertanyaan trivia, pertanyaan yang berkaitan dengan sejarah dan bidang STEM seperti teknik dan sains serta pengkodean umum. rekomendasi. Hal ini sebagian berkat kumpulan data yang jauh lebih besar: kumpulan 15 triliun token, atau ~750.000.000.000 kata yang mencengangkan — tujuh kali lipat ukuran set pelatihan Llama 2. (Dalam bidang AI, “token” mengacu pada bagian data mentah yang terbagi lagi, seperti suku kata “fan”, “tas”, dan “tic” dalam kata “fantastis.”)
Dari mana data ini berasal? Pertanyaan bagus. Meta tidak akan mengatakannya, hanya mengungkapkan bahwa ia mengambil dari “sumber yang tersedia untuk umum,” menyertakan kode empat kali lebih banyak dibandingkan kumpulan data pelatihan Llama 2, dan bahwa 5% dari kumpulan tersebut memiliki data non-Inggris (dalam ~30 bahasa) untuk meningkatkan kinerja pada bahasa selain bahasa Inggris. Meta juga mengatakan mereka menggunakan data sintetis – yaitu data yang dihasilkan AI – untuk membuat dokumen yang lebih panjang untuk dilatih oleh model Llama 3, pendekatan yang agak kontroversial karena potensi kelemahan kinerja.
“Meskipun model yang kami rilis hari ini hanya disesuaikan untuk keluaran bahasa Inggris, peningkatan keragaman data membantu model mengenali nuansa dan pola dengan lebih baik, dan bekerja dengan baik dalam berbagai tugas,” tulis Meta dalam postingan blog yang dibagikan dengan TechCrunch.
Banyak vendor AI generatif melihat data pelatihan sebagai keunggulan kompetitif dan dengan demikian menyimpannya serta informasi yang berkaitan dengannya. Namun rincian data pelatihan juga berpotensi menjadi sumber tuntutan hukum terkait kekayaan intelektual, yang merupakan salah satu penghambat untuk mengungkapkan banyak hal. Pelaporan terkini mengungkapkan bahwa Meta, dalam upayanya mengimbangi pesaing AI, pernah menggunakan eBook berhak cipta untuk pelatihan AI meskipun ada peringatan dari pengacara perusahaan; Meta dan OpenAI adalah subjek tuntutan hukum yang sedang diajukan oleh penulis termasuk komedian Sarah Silverman atas dugaan penggunaan data berhak cipta yang tidak sah oleh vendor untuk pelatihan.
Lalu bagaimana dengan toksisitas dan bias, dua masalah umum lainnya pada model AI generatif (termasuk Llama 2)? Apakah Llama 3 membaik di area tersebut? Ya, klaim Meta.
Meta mengatakan bahwa mereka mengembangkan saluran pemfilteran data baru untuk meningkatkan kualitas data pelatihan modelnya, dan memperbarui sepasang rangkaian keamanan AI generatif, Llama Guard dan CybersecEval, untuk mencoba mencegah penyalahgunaan dan pembuatan teks yang tidak diinginkan dari Llama 3 model dan lainnya. Perusahaan juga merilis alat baru, Code Shield, yang dirancang untuk mendeteksi kode dari model AI generatif yang mungkin menimbulkan kerentanan keamanan.
Namun, pemfilteran bukanlah hal yang mudah — dan alat seperti Llama Guard, CybersecEval, dan Code Shield hanya berfungsi sejauh ini. (Lihat: kecenderungan Llama 2 untuk membuat jawaban atas pertanyaan dan membocorkan informasi kesehatan dan keuangan swasta.) Kita harus menunggu dan melihat bagaimana kinerja model Llama 3 di alam liar, termasuk pengujian dari para akademisi pada tolok ukur alternatif.
Meta mengatakan bahwa model Llama 3 — yang sekarang tersedia untuk diunduh, dan mendukung asisten Meta AI Meta di Facebook, Instagram, WhatsApp, Messenger, dan web — akan segera dihosting dalam bentuk terkelola di berbagai platform cloud termasuk AWS, Databricks, Google Cloud, Hugging Face, Kaggle, WatsonX IBM, Microsoft Azure, NIM Nvidia, dan Snowflake. Di masa depan, versi model yang dioptimalkan untuk perangkat keras dari AMD, AWS, Dell, Intel, Nvidia dan Qualcomm juga akan tersedia.
Dan model yang lebih mumpuni akan segera hadir.
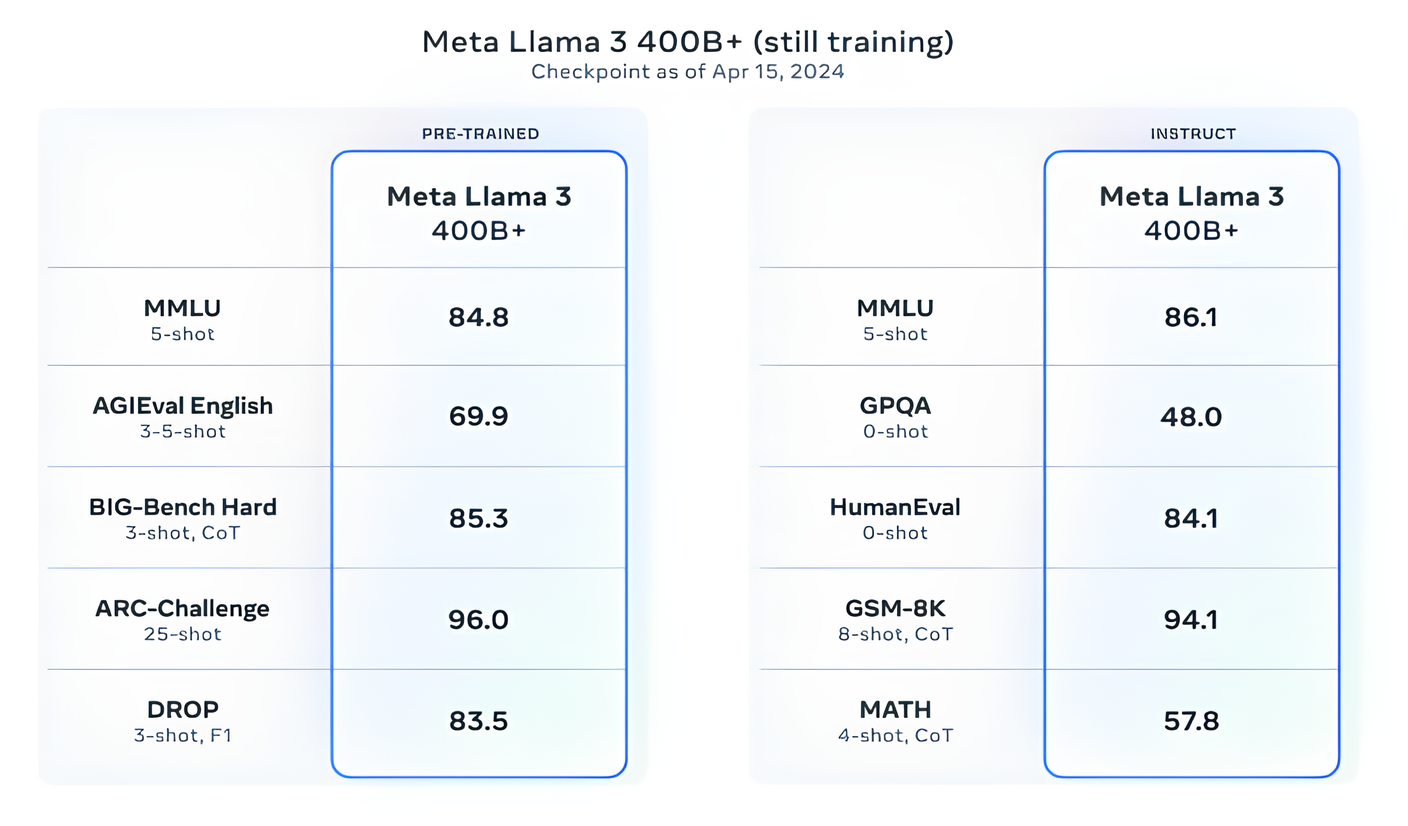
Meta mengatakan bahwa saat ini mereka sedang melatih model Llama 3 dengan ukuran lebih dari 400 miliar parameter — model dengan kemampuan untuk “berkomunikasi dalam berbagai bahasa,” mengambil lebih banyak data dan memahami gambar dan modalitas lain serta teks, yang akan menghadirkan seri Llama 3 sejalan dengan rilis terbuka seperti Hugging Face's Idefik2.
Kredit Gambar: Meta
“Tujuan kami dalam waktu dekat adalah menjadikan Llama 3 multibahasa dan multimodal, memiliki konteks yang lebih panjang, dan terus meningkatkan kinerja keseluruhan di seluruh sistem inti. [large language model] kemampuan seperti penalaran dan pengkodean,” tulis Meta dalam postingan blog. “Masih banyak lagi yang akan datang.”
Memang.



{kind=link}